央广网北京6月15日消息(记者 刘家怡)6月12日至13日,第八届北京智源大会在京举办。可重构计算架构代表企业清微智能携可重构超节点服务器、三维集成技术概念模型亮相展区。
“模型越做越大,算力却跟不上了。”在智算前沿论坛上,清微智能软件副总裁李彬开门见山。面对先进制程受限、摩尔定律放缓的双重挑战,清微智能在本次大会上提出——以架构补工艺、以集成超制程、以系统聚算力、以自主创生态。四步环环相扣,力图让国产算力从“可运行”真正走向“经济性”。
以架构补工艺:晶体管利用率突破70%
清微智能指出,传统架构芯片面临功耗墙、内存墙、通信墙层层限制,有效晶体管利用率不足40%。清微通过可重构数据流引擎,让计算单元根据数据流动按需重组,晶体管有效利用率一举突破70%,用成熟制程实现接近先进制程的有效算力。
清微智能的逻辑很明确:不依赖于制程工艺升级的限制,用架构重新定义效率。李彬介绍,该方案已在电力、政务、EDA、电信四大关键行业完成规模化部署。

清微智能软件副总裁李彬。(清微智能供图 央广网发)
以集成超制程:3.5D堆叠,“单车道”变“四车道”
如果“架构补工艺”解决的是计算效率的问题,那么“集成超制程”瞄准的则是“内存墙”。
清微智能展台上摆放的下一代AI芯片三维集成模型吸引了众多与会者驻足。传统2D芯片如同“单车道”,而清微采用3.5D异构堆叠与Chiplet架构,让可重构计算芯粒与DRAM存储芯粒实现三维垂直堆叠,形成立体贯通的“四车道”,大幅提升数据传输效率。
突破的关键在于将信号传输距离从毫米级压缩至微米级,访存带宽比传统HBM高出数倍。算力引擎可以持续满负荷运转,使得千亿参数大模型参数搬运的延迟大幅下降。

清微智能展台前人流如织。(清微智能供图 央广网发)
以系统聚算力:超节点互联成本降低90%
大模型能力的飞速增长,正在从根本上改变算力供给方式。李彬指出,近年来模型规模从十亿、百亿、千亿到万亿参数飞速增长,需要极大的算力支撑,传统的单机离散供给已无法满足需求,集约式集群部署成为必然。“超节点技术本身并不新,只是模型的进化让它终于有了用武之地。”
李彬在采访中介绍,清微的超节点方案摒弃了依赖外部交换机、以太网卡的互联架构,从芯片层面内置高速通信能力,最多可将4096颗可重构计算芯片以访存语义进行基于Mesh拓扑的点对点直连,形成一张高带宽、低延时网络。该超节点算力突破每秒500千万亿次,互联成本较国外同类方案降低90%。“交换机和光模块在算力集群总成本中占比很高,此方案几乎可以把这部分成本省掉。”
据了解,今年3月,该成果入选2026中关村论坛重大科技成果,在北京市某算立场项目中,清微部署的4K超节点服务器成为首个全域就绪、全程贯通的国产算力解决方案。目前,该成果已融入国家“东数西算”工程及十余个省份的智算中心。
以自主创新生态:统一软件生态加速国产替代
“生态建设的重要性,比芯片本身的技术创新还重要。”李彬坦言。过去两三年,清微已意识到,若每家芯片公司都用自己的软件栈,用户面对多种国产芯片将难以适配。因此,清微智能深度参与国产AI算力统一软件生态建设,与智源 FlagOS实现全栈兼容,适配规模在非GPU架构中与华为昇腾并列前二。
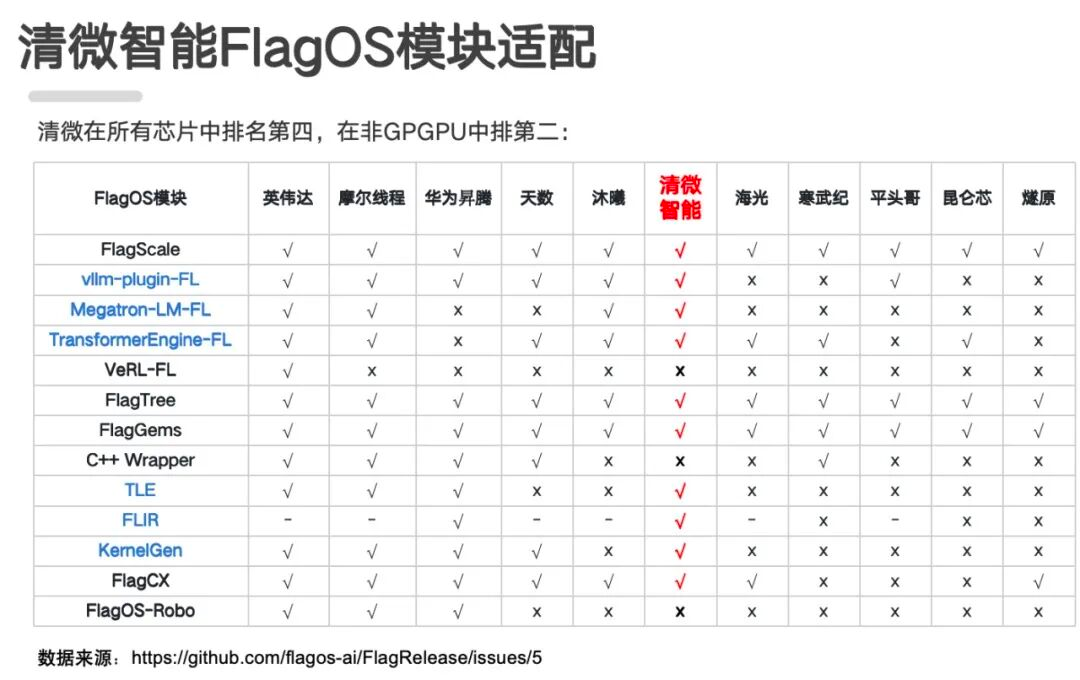
清微智能与FlagOS的技术适配。(清微智能供图 央广网发)
这一策略的效果已经显现。李彬以DeepSeek模型适配为例:去年R1模型发布时,各家国产芯片平均需要1~2个月才能完成适配;而今年V4版本发布当天,多家国产芯片便同期完成适配,并通过FlagRelease发布了模型推理镜像。
李彬表示,统一软件生态的意义不仅在于节省开发者的适配时间,更深层次的价值在于让国产算力生态中的各方发挥各自优势——芯片厂商专注架构等硬件创新,软件生态将算力的易用性拉满。“这种极致的专注和协同式创新,才能让国产算力有可能用最短的时间赶超领先国家的水平。”
他判断:“未来1至2年内,国产算力替代的临界点将真正到来。用户选择国产算力芯片,单纯会因为好用、性价比高。”
Copyright @ 2001-2013 zq.movesh.com All Rights Reserved
正确网 版权所有